전통적으로, 추천 시스템은 클러스터링, KNN, Matrix factorization을 기반으로 했습니다.
하지만 최근에는 딥러닝이 모든 분야에 접목되기 시작했고 추천 시스템 역시 예외는 아니었습니다.
코드: https://www.kaggle.com/code/mmvv11/deep-learning-based-recommender-systems
참고 원본: https://www.kaggle.com/code/jamesloy/deep-learning-based-recommender-systems
추천 시스템에서 implicit, explicit feedback의 차이점 파악
본격적으로 모델을 만들기 전에 추천 시스템에서는 implicit, explicit feedback 차이를 파악하는 것이 굉장히 중요합니다.
그리고 왜 모던 추천 시스템에서는 implicit feedback 기반 모델을 만드는지 이해해야 합니다.
우선 explicit feedback입니다.
이는 굉장히 명확한 피드백을 의미합니다.
예를들어 배민에서 손님이 가게에 별점을 주는 것과 같은 것들을 명확한 피드백이라고 합니다.
또는 유튜브의 좋아요, 싫어요 등이 이에 해당합니다.
물론 이런 피드백이 직관적이고 좋지만, 이는 굉장히 희소하다는 특징이 있습니다.
현실적으로 하루에 유튜브 영상 100개 본다고 치면 좋아요 누르는 것은 5개나 될까요?
다음은 implicit feedback입니다.
이는 암묵적인 피드백을 의미합니다.
예를들면, 유튜브 영상을 시청하는 행위 자체가 그 사람의 선호도를 파악할 수 있는 단서라고 볼 수 있습니다.
이런 암묵적인 피드백의 장점은 데이터양이 충분하다는 점입니다.
사용자가 인터넷을 하며 클릭하는 것이 모두 데이터가 될 수 있기 때문입니다.
하지만, 이 역시 단점이 있습니다.
데이터가 존재한다고 해서 모두 그것을 좋아한다고 가정할 수는 없다는 점입니다.
그럼 어떻게 부정적이라는 것을 파악할 수 있을까요?
다양한 방법이 존재하지만, 그 중 하나는 negative sampling 이라는 방식입니다.
데이터 전처리
Movielens-20m 데이터셋을 활용합니다.
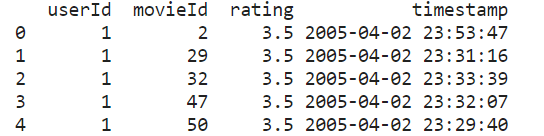
무비렌즈 데이터는 위와 같이 생겼습니다.
"유저 인덱스, 영화 인덱스, 평점, 시간" 이런 컬럼이 존재합니다.
Train-Test Split

시간을 나타내는 timestamp 컬럼을 사용해서 train-test 셋을 나눠줄 것입니다.
여기서는 leave-one-out 방법을 적용합니다.
가장 최근에 본 영화를 test 데이터로 사용하겠다는 것입니다.
다시 말하자면, 모델에 아바타, 존카터, 인터스텔라를 학습시키고 top-k 추천을 한 다음, top-k 내부에 가디언즈 오브 갤럭시가 존재하는지 보는 것입니다.
무비렌즈의 Explicit data를 Implicit data로 바꾸기
무비렌즈에 존재하는 rating 컬럼은 실제로 유저가 영화에 준 평점이라 explicit feeback이라고 할 수 있습니다.
하지만, 목적은 implicit data를 사용해서 추천을 하는 것입니다.
따라서, 평점이 존재한다면 그저 유저와 영화 사이에 interaction이 존재한다고 가정하고 1로 설정합니다.
반대로 평점이 존재하지 않는 영화에 대해서는 interaction이 존재하지 않는다 가정하고 0으로 설정합니다.
이렇게 하면 평점이라는 explicit data를 implicit data로 바꾼 것이 됩니다.
(물론 이 작업은 설정하기 나름일 것입니다. 예를들어 rating이 3점 이상이라면 1, 아니라면 0. 이런식으로 긍정/부정을 나누는 것도 방법이겠죠. 이는 탐험적으로 시나리오를 바꿔가며 모델 성능을 확인하며 판단해야할 문제라고 생각합니다.)
이렇게 implicit data로 바꿨기 때문에, 추천 모델에서 목적하는 바는, 유저가 영화에 평점을 몇점을 주느냐 예측하는 것이 아닙니다.
이제는 유저와 영화 사이에 interaction이 있을까 없을까? 이를 확률로 예측하는 문제가 되는 것입니다.
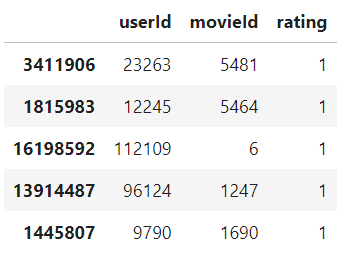
이런식으로 데이터가 존재한다면 interaction이 존재한다고 할 수 있는 것이며, 따라서 rating 컬럼을 1로 바꾸면 됩니다.
네거티브 샘플링 (4:1)
하지만, 위와 같이 모든 데이터에 1만 있으면 모델이 학습을 못합니다.
0이라는 데이터가 있어야 모델이 학습할 수 있겠습니다.
따라서 네거티브 샘플링을 해줍니다.
이는 랜덤으로 뽑은 영화를 기존 유저가 interaction한 적이 없다면 0으로 데이터를 추가해주는 것입니다.
그리고 이를 4:1 비율로 설정해줍니다. (물론 이것도 실험적으로 네거티브 샘플 비율을 바꾸며 실험해보면 좋습니다.)
예를들어, 3번 유저가 지금까지 1, 4번이라는 두개의 영화를 보았다면, 8개의 네거티브 샘플링을 해주는 것입니다.
NCF(Neural Collaborative Filtering) 모델
딥러닝 기반 추천 모델은 Neural Collaborative Filtering 을 사용합니다.
임베딩의 이해
임베딩이란 고차원 데이터를 저차원 벡터로 옮긴 것입니다.
예를들어 현재 상당히 많은 데이터가 존재합니다.
이를 바탕으로 이 유저가 액션을 좋아하느냐, 로맨스를 좋아하느냐라는 단 두개의 차원으로 해당 유저의 preference를 표현하는 것이 목적이라고 합니다.
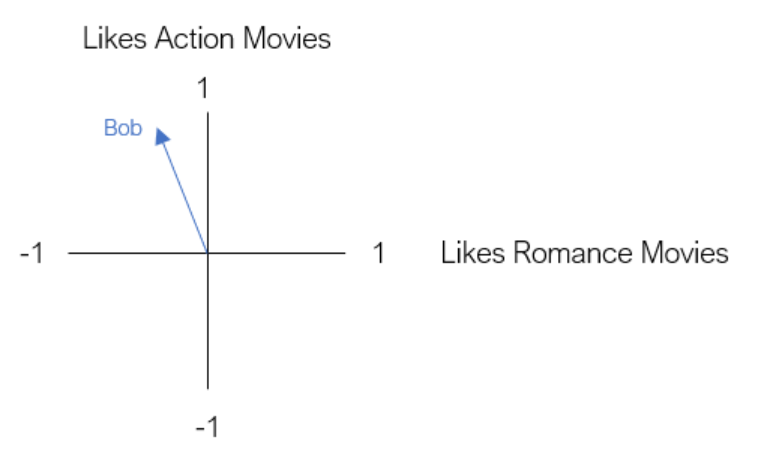
Bob이라는 유저가 있다고 생각해보면, 이 사람은 액션 영화를 좋아하지만 로맨스 영화는 그닥 좋아하지 않는다라는 임베딩을 얻었다고 가정하면 그의 선호도는 위 사진과 같이 표현할 수 있습니다.
이것이 바로 임베딩입니다.
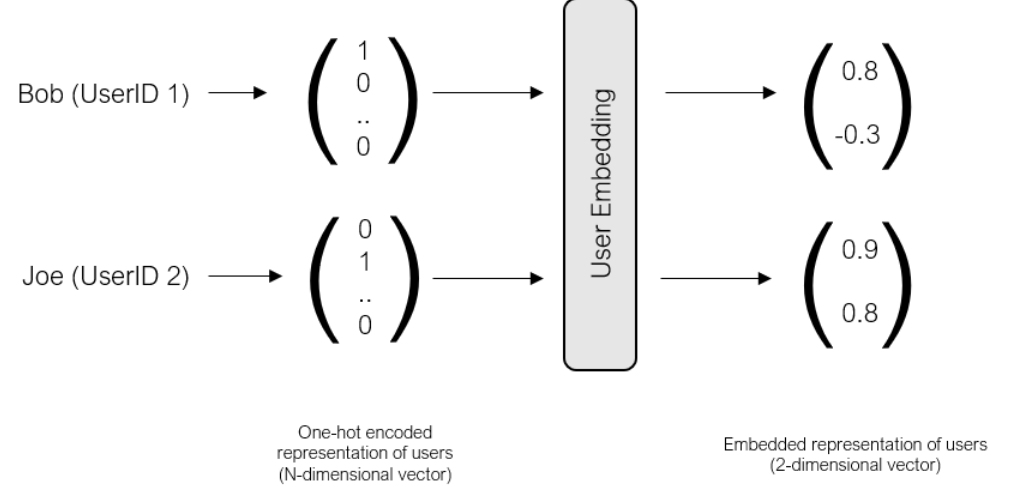
사실 수많은 유저가 존재하는 고차원의 벡터가 존재하겠지만, 각 유저를 원-핫 벡터로 표현하고 임베딩을 거쳐 2차원 임베디드 벡터로 나타내는 것입니다.
예시에서는 직관적인 이해를 위해 2차원이라고 했지만 이는 설정하기 나름입니다.
차원이 늘어날수록 수용력이 늘어나서 유저의 선호도를 더 구체적으로 표현할 수 있습니다.
실험에서는 8차원을 사용합니다.
NCF 모델 구조
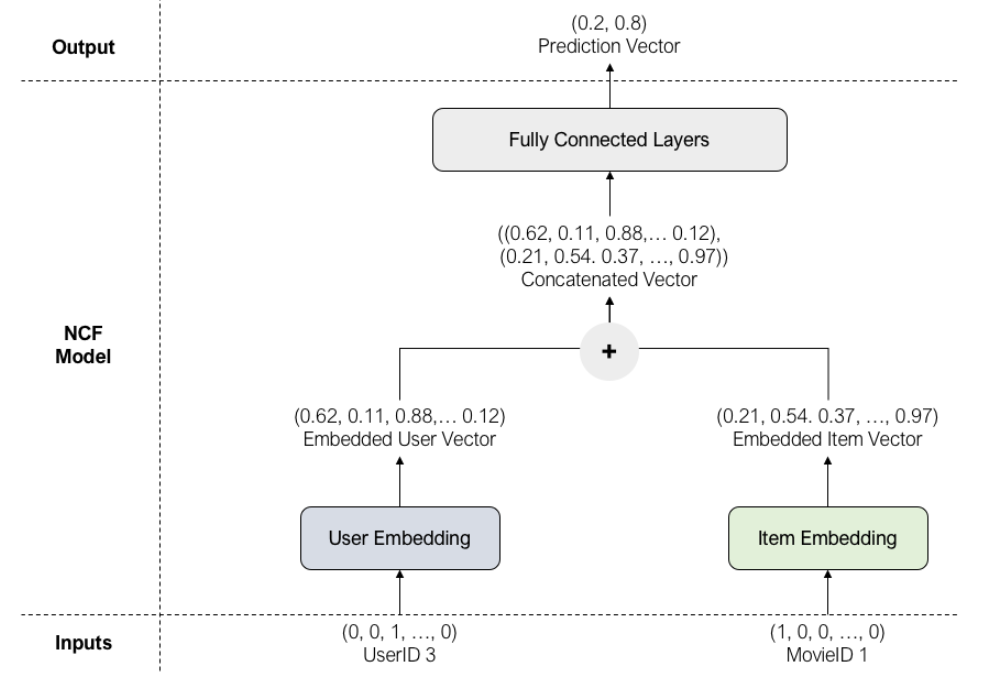
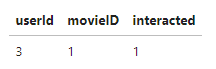
만약 이런 데이터가 있다고 가정하고, 모델 아키텍쳐를 이해해봅니다.
데이터: 3번 유저가 1번 영화와 interacted함.
- 3번 유저는 원-핫벡터로 표현되어 임베딩 레이어를 지나 8차원 벡터로 표현됩니다.
- 1번 아이템 역시 같은 로직을 거칩니다.
- 유저 임베딩, 아이템 임베딩을 concat하여 이를 FC 레이어를 거칩니다.
- 최종적으로 시그모이드를 통해 결과를 출력합니다.
- 예시에서는 0.8이라는 결과를 얻습니다. 즉, interact 할 확률이 80% 된다는 결과를 얻은 것입니다.
모델 평가 - Hit ratio
추천 시스템에서는 단순히 Accuracy나 RMSE를 적용해서 모델을 평가하기에는 fair하지 않습니다.
왜냐하면, Accuracy는 분류와 같은 문제에서는 합리적입니다. 모델이 분류를 잘했으면 잘했다고 해주면 되는 것이고.
RMSE 같은 경우엔 회귀와 같은 문제에서 합리적입니다. 모델이 실제 데이터와 얼마나 많이 떨어져있는지, 최대한 가까우면 잘했다고 칭찬해주면 되는 것이기 때문입니다.
하지만 추천 시스템에서는 이런 메트릭은 적절하지 못합니다.
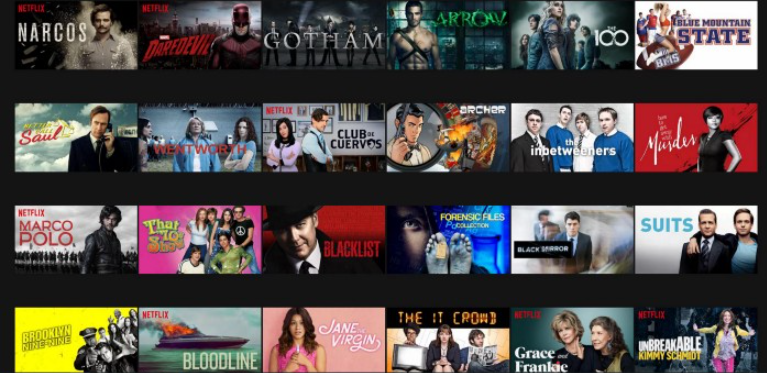
넷플릭스는 수많은 영화를 추천해줍니다.
그리고 우리는 그중에 하나만 클릭해서 재밌게 봐도 괜찮은 추천이라고 생각할 것입니다.
이게 바로 추천 시스템에 적절한 메트릭이 필요한 이유라고 할 수 있습니다.
추천 시스템에서는 유저가 모든 아이템과 interact하게 하는 것을 목적으로 하지 않습니다.
추천한 것들 중 최소 1개라도 먹히면 추천은 잘 진행된 것이라고 할 수 있는 것입니다.
따라서 다음과 같이 추천 시스템을 평가합니다.
- 각 유저에 대해서, 해당 유저가 이전에 본적 없는 99개의 영화를 랜덤으로 선정합니다.
- 테스트 데이터로 존재하는 1개의 영화를 99개 영화에 끼워서 데이터를 구성합니다.
- 총 100개의 영화를 NCF 모델에 넣어서 유저와 interaction할 확률을 구합니다.
- 확률이 가장 높은 10개의 영화를 선정합니다.
- Top-10 추천 영화 중 테스트 데이터가 포함되어 있는지 확인합니다. 만약 포함되어 있다면 추천은 Hit! 한 것입니다.
- 모든 유저에 대해 이 과정을 진행합니다.
- Hit 갯수를 총 유저 수로 나눠서 Hit 평균을 구합니다. 이것을 Hit ratio로 모델 성능을 평가합니다.
여기까지가 NCF를 이용한 추천에 대한 설명이었습니다.
NCF는 유저, 아이템 임베딩을 활용하여 이를 뉴럴넷에 넣어 추천을 하는 간단하고 강력한 모델입니다.
'인공지능 > 추천 시스템의 기초' 카테고리의 다른 글
| 추천 시스템 평가 지표 1. Accuracy : MAE, RMSE (0) | 2022.12.21 |
|---|
